In the world of modern telecom, Cloud Call Centers, and UCaaS (Unified Communications as a Service), your platform's survival comes down to one thing: how well it scales.
Old-school billing systems were built for a different era, one where phone calls were predictable, and data could be processed in slow, nightly batches. Today, that approach doesn't work. With the explosion of cloud communications and micro-usage tracking, a modern billing setup needs to process hundreds of millions of events every single day without breaking a sweat.
When your system is hitting over 100 million Call Detail Records (CDRs) or usage logs daily, traditional systems hit a wall. They slow down, cause system-wide lag, and leave you with a massive backlog of unrated calls. For growing MVNOs and SaaS providers, this isn't just an annoying IT problem, it directly eats away at your profit margins, strains partner relationships, and stops your business from scaling.
Let's dive into how to design a reliable telecom CDR pipeline using a modern, high-volume rating engine. We will look at what it takes to move away from slow, risky batch processing to a real-time, zero-drop billing ecosystem that handles complex corporate rate plans smoothly.
1. The Scaling Crisis: Why Old Billing Systems Choke Under Heavy Loads
To understand how to build a high-speed system, we first need to look at why older software fails when trying to handle usage data ingestion at scale.
The Problem with Traditional Systems
Most older billing engines rely on synchronous processing with the relational databases. In these systems, every time a new call log or a CDR comes in, the engine has to ask the system database: "Who owns this account? What is their current balance? What rate plan do they have?" Once it calculates the cost, it updates that database row with the new balance.
If you are only processing a few thousand calls a day, this step-by-step approach works fine. But when your business grows and traffic spikes to thousands of calls per second, traditional systems choke. This causes a major bottleneck in CDR processing.
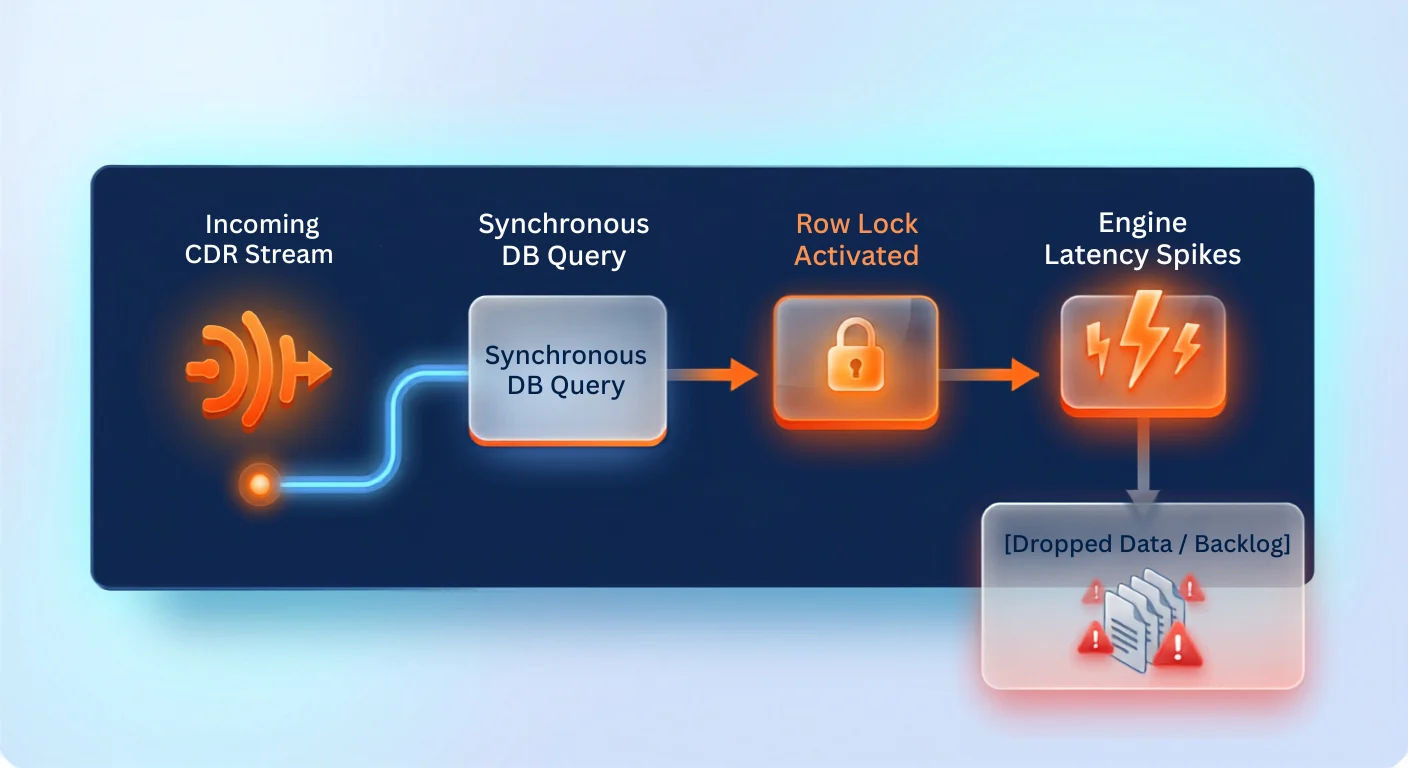
Because hundreds of calls are trying to update the exact same corporate account balance or rate table at the very same microsecond, the database forces them to wait in line. This creates a massive traffic jam in your software, causing memory overloads and system timeouts.
The Domino Effect of System Lag
When the rating engine slows down, it triggers a chain reaction across your entire network:
- The Backlog Goes Out of Control: Unprocessed call logs pile up. If your system takes two hours to process just one hour of peak traffic, you will never catch up, and your billing cycles will get delayed by days.
- Lost Data: To keep the whole system from crashing, fragile older middleware will often just drop out-of-order data packets entirely.
- Complete Blindness: If you can't calculate usage costs in real time, you lose track of what is happening on your network right now. This makes it impossible to enforce credit limits before a customer overspends.
The Headaches for Your Team
When technology fails, humans have to step in. Network operations teams end up spending countless hours digging through raw text logs, writing messy scripts to clean up data, and manually checking CSV files to find out why numbers don't match.
This manual work opens the door to major human errors, keeps your billing team trapped in spreadsheets, and delays your invoices, meaning it takes much longer for cash to actually enter your business.
2. The Blueprint of a Modern, Reliable CDR Pipeline
A modern architecture handles usage data ingestion at scale by breaking the process into separate, independent steps. Instead of forcing one system to do everything at once in a straight line, it uses an asynchronous, event-driven setup.
The pipeline is split into four separate layers that talk to each other but run independently. If one layer slows down, the others keep working normally.
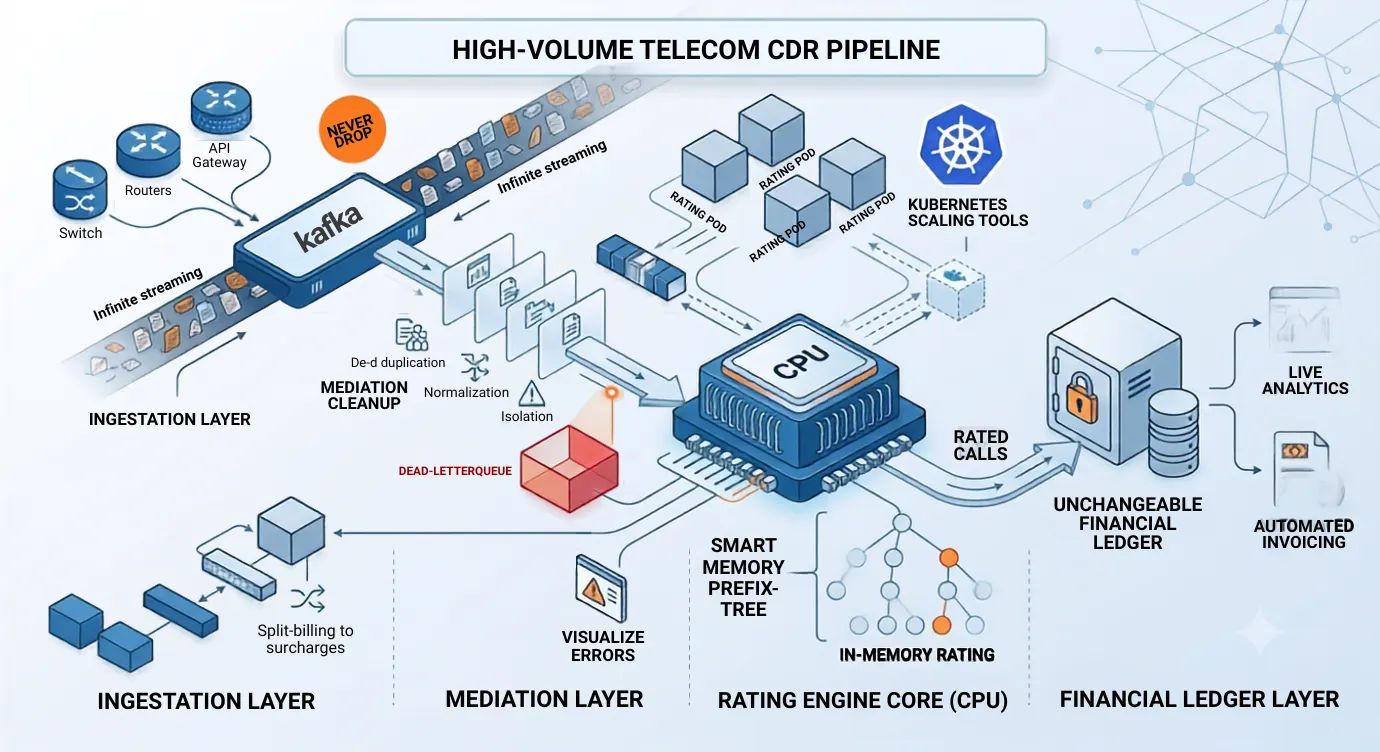
A. The Ingestion Layer (Never Drop a Log)
The entry point of your pipeline must be completely separated from the actual billing calculations. Think of it as a high-speed, digital waiting room designed to catch millions of data points instantly without trying to organize them yet.
The Tech: Distributed streaming platforms like Apache Kafka.
How it works: Raw streams from network switches, routers, and API gateways hit this layer instantly. The system simply marks them as "received" and holds them safely. Even if your billing engine is down for a quick update, this layer keeps running, ensuring you never lose a single call record.
B. The Mediation Layer (Cleanup and Organize)
Raw network logs are incredibly messy. A single phone call or video session might generate three different logs: one when the call starts, an update in the middle, and another when it ends. These logs often arrive out of order and in completely different file formats.
The mediation layer pulls these raw records from the waiting room and cleans them up using three steps:
- De-duplication: It scrubs out identical records caused by network retries so you don't charge a customer twice for the same call.
- Normalization: It translates different network languages into one standard format.
- Isolation: Clean records are sent straight to the billing line. If a record is corrupted or broken, it gets tossed into a "dead-letter queue" (an isolation room) where tech teams can fix it later without stopping the main conveyor belt.
C. The High-Volume Rating Engine Core
This is where the heavy lifting happens. Instead of making slow round-trips to a traditional database for every single call, a modern high-volume rating engine keeps all active account balances, company structures, and complex rate sheets directly in its temporary computer memory (in-memory parallel processing).
When a clean call log arrives, the engine calculates the cost in less than a millisecond because it doesn't have to wait on a slow hard drive. It processes thousands of calls simultaneously across parallel tracks, then saves the results to the permanent database quietly in the background.
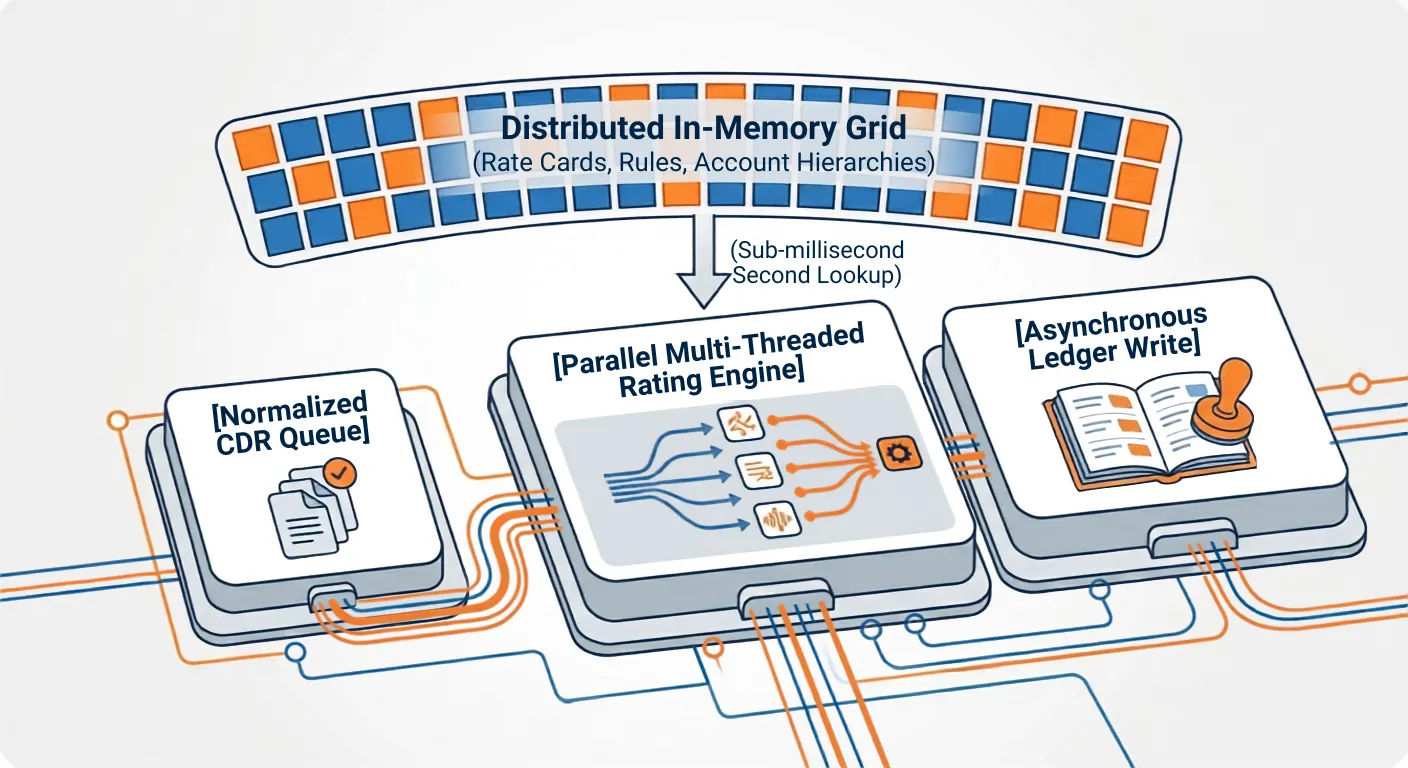
D. The Financial Ledger Layer
Once a call is rated, it is written into an unchangeable financial sub-ledger. This layer tracks unbilled usage in real time, feeds your live analytics dashboards, and prepares the data for automated invoicing at the end of the month.
3. Handling the Hard Stuff: Real-Time Charging and Company Hierarchies
Processing over 100 million events requires smart shortcuts to solve the unique math problems found in telecom and UCaaS usage tracking.
Real-Time Voice Charging
Rating a phone call isn't as simple as multiplying minutes by a flat rate. The engine has to calculate a variety of moving parts instantly:
- Location Tracking: Checking phone numbers against thousands of international country codes, mobile networks, and local zones to find the right price.
- Custom Rounding rules: Applying tricky intervals like 1/1 (charging by the exact second) or 60/1 (charging for a full minute first, then by the second).
- Prepaid Accounts: For users on a strict budget, the engine must look at the balance while the call is live, ticking down the money second-by-second and cutting off the line if the balance hits zero.
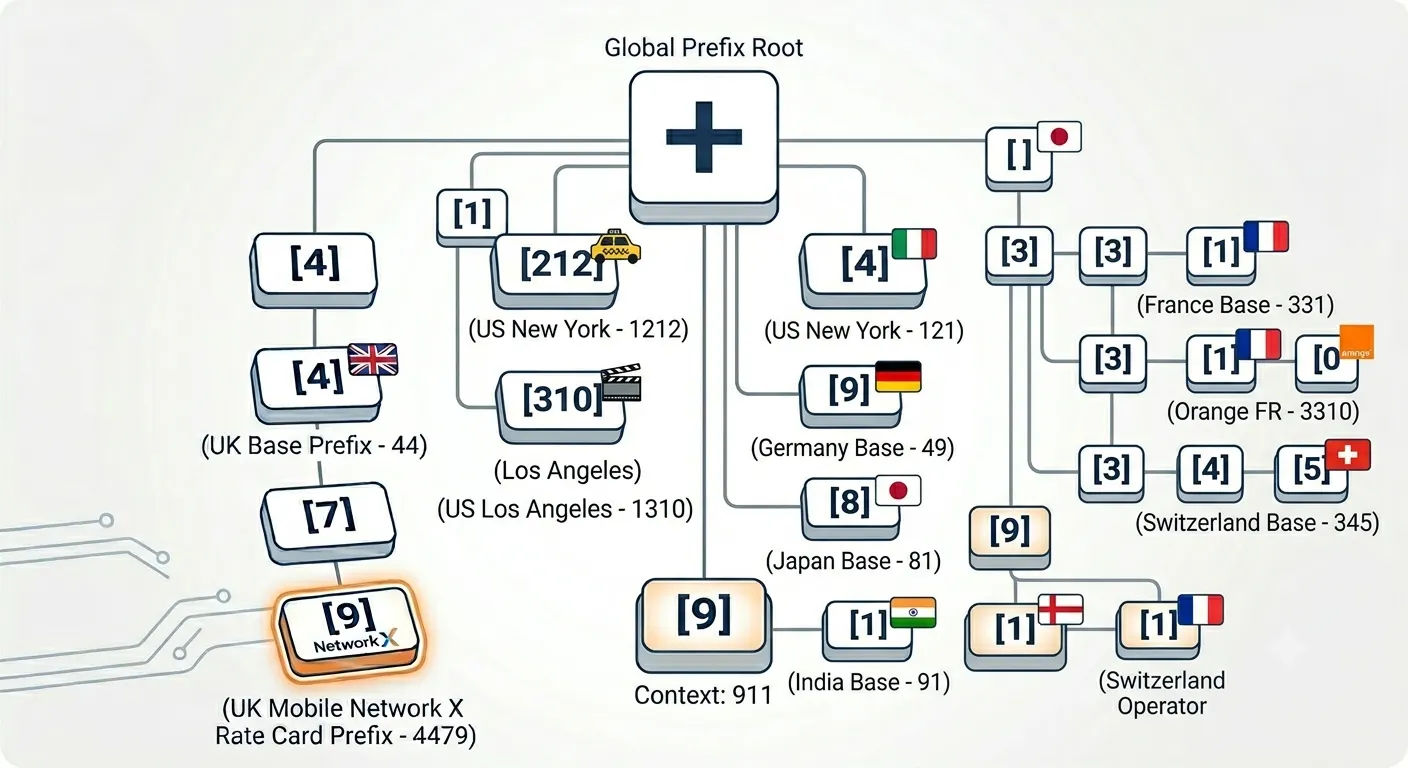
Smart Memory Shortcuts for Complex Rates
To keep speeds under a millisecond, the system uses a digital sorting method called a "prefix tree" (or Trie structure) in its memory.
When a phone number comes in (like +44 7911...), the engine traces down a branch of the tree instantly to grab the exact rate for that specific mobile network. It completely skips the slow process of searching through millions of rows in a database table.
Multi-Tier Billing for Large Enterprise Customers
Large corporate clients add another layer of complexity. They don't just have single users; they have complex organizational trees:
Enterprise → Region (North America) → Department (Sales) → Individual User
A modern billing system can look at an individual employee's usage while simultaneously applying rules for the entire corporation:
- Shared Resource Pools: Tracking a single bucket of 10,000 minutes shared across 5,000 corporate employees, where every live call updates the master pool instantly.
- Split-Billing: Automatically dividing a single call log into two bills. For example, routing the base cost of an international call to the corporate account, but sending any premium surcharges directly to the specific department's budget.
4. How the System Runs and Scales in the Real World
A great blueprint is useless if it's too hard to manage, monitor, or scale when real-world traffic hits.
Scaling Up Automatically in the Cloud
Modern rating engines are built using cloud-native containers (like Docker and Kubernetes).
Because communication traffic changes predictably, surging during business hours and dropping off to almost nothing at midnight, your billing engine should expand and shrink automatically.
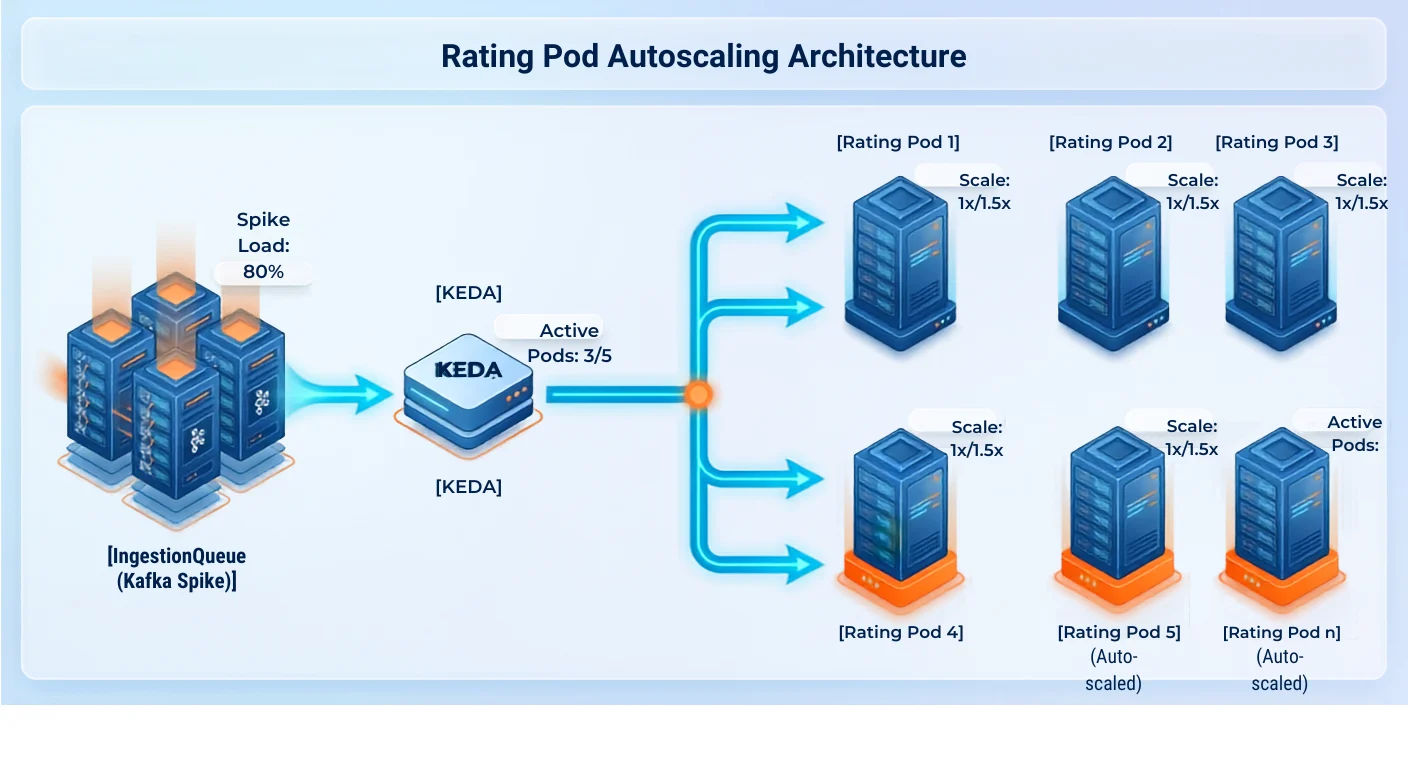
By using automated scaling tools, the system watches your waiting room queue. If a massive burst of traffic arrives, the cloud automatically spins up five or ten extra "mini-engines" to process the backlog in seconds, then turns them off when traffic slows down to save you infrastructure costs.
Clear Dashboards and Easy Fixes
When you are dealing with 100 million logs, old text error files are useless. No human can read through a billion lines of text to find one broken error.
Instead, modern systems tag every single call log with a unique digital tracking code. If a call fails to bill because of an unconfigured country code, it shows up on a visual dashboard (like Grafana) instantly.
Your data team can fix the missing rate on the dashboard and click "Reprocess". The system will instantly send those millions of isolated error logs back into the live billing stream seamlessly, without needing complex code changes or rebuilds.
5. The Real-World Payoff: Moving from Legacy Issues to Enterprise Growth
Upgrading from a fragile batch system to an automated, high-volume ecosystem creates a massive, measurable difference across your entire company.
| Feature | Old Batch Systems | Modern High-Volume Engine |
|---|---|---|
| Limits & Bottlenecks | Breaks or locks up at >100k events. | Handles 100M+ loads easily using parallel tracks. Horizontally scalable for even higher loads. |
| Data Security | Drops messy or out-of-order logs to avoid crashes. | Zero-drop capture with an isolation room for quick fixes. |
| Speed | 12 to 48-hour delays; you are always looking at old data. | True real-time voice charging & rating under a millisecond. |
| Team Effort | Manual script writing, parsing files, and fixing Excel errors. | Fully automated, cloud-native processing pipelines. |
| Revenue Losses | High, unbilled calls slip through system cracks. | Eliminated; every single event is tracked and billed accurately. |
| Invoicing Accuracy | Frequent mistakes on complex corporate accounts. | Flawless multi-tier updates and automated split-billing. |
For Your Business Development Team: An Agile Monetization
Legacy systems restrain your product catalog. If your business team waits for three months of server side development just to launch a new enterprise pricing model, you are actively losing market share to agile competitors.
Modernizing your rating pipeline transforms billing from a back-office utility into a strategic commercial asset. Because the rating logic is decoupled from rigid designs, business units can instantly design and deploy personalized product bundles. Whether you are pairing flat UCaaS seat licenses with metered, real-time AI token usage, or rolling out dynamic MVNO data tiers, you can launch new monetization models in a few days rather than quarters, securing an immediate first-mover advantage.
Fast time-to-market prevents customer churn. When an enterprise client demands a hybrid tier, delivering it in days rather than months prevents them from slipping away to a more nimble competitor.
For Your Tech Team: No More Midnight Crises
By separating data ingestion from the actual calculations and automating how errors are handled, your engineering team can finally stop playing firefighter.
Instead of chasing down missing records or writing quick database patches, your Dev and DevOps teams can focus on building new features. You can launch new product bundles, data plans, or enterprise discounts instantly without taking your systems offline.
For Your Finance Team: Stop Losing Money and Get Paid Faster
From a financial perspective, a modern system acts as an automated security guard for your revenue:
- Plug Million-Dollar Revenue Leakage: In high-volume operations, even a seemingly negligible 0.1% unrated call drop rate on 100M daily events translates to 100,000 completely unbilled sessions every day. Over a fiscal year, this silent leakage quietly erodes millions in straight bottom-line profit. Modern telco-grade billing system captures and validates every single event, instantly recovering those lost margins.
- Drastically Reduce Days Sales Outstanding (DSO): Because every usage event is tracked, validated, and fully rated in true real time, month-end corporate invoice generation is compressed from a multi-week operational slog into a few minutes. This dramatically accelerates your cash conversion cycle and frees up working capital.
- Optimize Cloud Infrastructure Spend (OpEx): Rather than paying for over-provisioned, idle on-premise hardware or database clusters built just to survive peak traffic hours, cloud-native automated scaling aligns your infrastructure spend directly with traffic volume. This utility-driven operational model can reduce your baseline compute costs by up to 40%.
- Fewer Client Disputes: Corporate clients get clear, itemized invoices that match their actual real-time dashboard data. This transparency cuts down on billing arguments, protects your customer support team, and keeps your enterprise clients happy.
Conclusion
Processing hundreds of millions of usage records is a software design challenge, one that requires an enterprise-grade architecture. Trying to force high-velocity, modern cloud communication logs through rigid old billing systems will always cause lags, missing data, and lost profits.
An enterprise-grade system needs to be built from the ground up to be independent and event-driven, combining flexible data cleanup with an advanced, in-memory high-volume rating engine.
By upgrading to a high-performance platform like EarnBill, scaling providers can plug revenue leaks, eliminate manual backend work, and turn their billing infrastructure into a powerful asset built for long-term growth.
Scale Your CDR Pipeline to 100M+ Events
See how EarnBill's high-volume rating engine handles massive telecom CDR pipelines with sub-millisecond processing, zero data drops, and cloud-native autoscaling.